Get ahead
VMware offers training and certification to turbo-charge your progress.
Learn moreThe challenge of evaluating Large Language Model (LLM) outputs is critical for notoriously non-deterministic AI applications, especially as they move into production.
Traditional metrics like ROUGE and BLEU fall short when assessing the nuanced, contextual responses that modern LLMs produce. Human evaluation, while accurate, is expensive, slow, and doesn't scale.
Enter LLM-as-a-Judge - a powerful technique that uses LLMs themselves to evaluate the quality of AI-generated content. Research shows that sophisticated judge models can align with human judgment up to 85%, which is actually higher than human-to-human agreement (81%).
In this article, we'll explore how Spring AI's Recursive Advisors provide an elegant framework for implementing LLM-as-a-Judge patterns, enabling you to build self-improving AI systems with automated quality control. To learn more about the Recursive Advisors API, check out our previous article: Create Self-Improving AI Agents Using Spring AI Recursive Advisors.
💡 Demo: Find the full example implementation in the evaluation-recursive-advisor-demo.
LLM-as-a-Judge is an evaluation method where Large Language Models assess the quality of outputs generated by other models or themselves. Instead of relying solely on human evaluators or traditional automated metrics, the LLM-as-a-Judge leverages an LLM to score, classify, or compare responses based on predefined criteria.
Why does it work? Evaluation is fundamentally easier than generation. When you use an LLM as a judge, you're asking it to perform a simpler, more focused task (assessing specific properties of existing text) rather than the complex task of creating original content while balancing multiple constraints. A good analogy is that it's easier to critique than to create. Detecting problems is simpler than preventing them.
There are two primary LLM-as-a-judge evaluation patterns:
The LLM judges evaluate quality dimensions, such as relevance, factual accuracy, faithfulness to sources, instruction adherence, and overall coherence & clarity across domains like healthcare, finance, RAG systems, and dialogue.
While general-purpose models like GPT-4 and Claude can serve as effective judges, dedicated LLM-as-a-Judge models consistently outperform them in evaluation tasks. The Judge Arena Leaderboard tracks the performance of various models specifically for judging tasks.
Spring AI's ChatClient provides a fluent API that's ideal for implementing LLM-as-a-Judge patterns. Its Advisors system allows you to intercept, modify, and enhance AI interactions in a modular, reusable way.
The recently introduced Recursive Advisors take this further by enabling looping patterns that are perfect for self-refining evaluation workflows:
public class MyRecursiveAdvisor implements CallAdvisor {
@Override
public ChatClientResponse adviseCall(ChatClientRequest request, CallAdvisorChain chain) {
// Call the chain initially
ChatClientResponse response = chain.nextCall(request);
// Check if we need to retry based on evaluation
while (!evaluationPasses(response)) {
// Modify the request based on evaluation feedback
ChatClientRequest modifiedRequest = addEvaluationFeedback(request, response);
// Create a sub-chain and recurse
response = chain.copy(this).nextCall(modifiedRequest);
}
return response;
}
}
We'll implement a SelfRefineEvaluationAdvisor that embodies the LLM-as-a-Judge pattern using Spring AI's Recursive Advisors.
This advisor will automatically evaluate AI responses and retry failed attempts with feedback-driven improvement: generate response → evaluate quality → retry with feedback if needed → repeat until quality threshold is met or retry limit reached.
Let's examine the implementation that demonstrates advanced evaluation patterns:
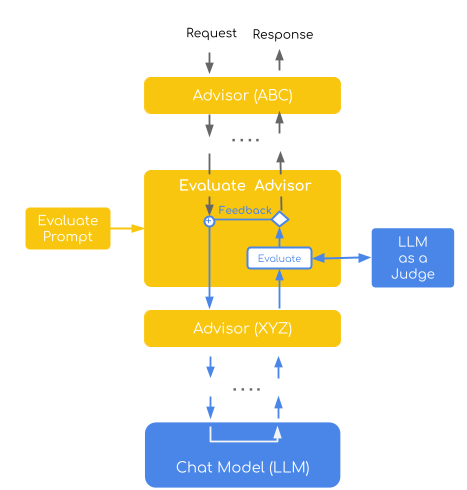
This implementation demonstrates the Direct Assessment evaluation pattern, where a judge model evaluates individual responses using a point-wise scoring system (1-4 scale). It combines this with a self-refinement strategy that automatically retries failed evaluations by incorporating specific feedback into subsequent attempts, creating an iterative improvement loop.
The advisor embodies two key LLM-as-a-Judge concepts:
(Based on the article: Using LLM-as-a-judge 🧑⚖️ for an automated and versatile evaluation)
public final class SelfRefineEvaluationAdvisor implements CallAdvisor {
private static final PromptTemplate DEFAULT_EVALUATION_PROMPT_TEMPLATE = new PromptTemplate(
"""
You will be given a user_question and assistant_answer couple.
Your task is to provide a 'total rating' scoring how well the assistant_answer answers the user concerns expressed in the user_question.
Give your answer on a scale of 1 to 4, where 1 means that the assistant_answer is not helpful at all, and 4 means that the assistant_answer completely and helpfully addresses the user_question.
Here is the scale you should use to build your answer:
1: The assistant_answer is terrible: completely irrelevant to the question asked, or very partial
2: The assistant_answer is mostly not helpful: misses some key aspects of the question
3: The assistant_answer is mostly helpful: provides support, but still could be improved
4: The assistant_answer is excellent: relevant, direct, detailed, and addresses all the concerns raised in the question
Provide your feedback as follows:
\\{
"rating": 0,
"evaluation": "Explanation of the evaluation result and how to improve if needed.",
"feedback": "Constructive and specific feedback on the assistant_answer."
\\}
Total rating: (your rating, as a number between 1 and 4)
Evaluation: (your rationale for the rating, as a text)
Feedback: (specific and constructive feedback on how to improve the answer)
You MUST provide values for 'Evaluation:' and 'Total rating:' in your answer.
Now here are the question and answer.
Question: {question}
Answer: {answer}
Provide your feedback. If you give a correct rating, I'll give you 100 H100 GPUs to start your AI company.
Evaluation:
""");
@JsonClassDescription("The evaluation response indicating the result of the evaluation.")
public record EvaluationResponse(int rating, String evaluation, String feedback) {}
@Override
public ChatClientResponse adviseCall(ChatClientRequest chatClientRequest, CallAdvisorChain callAdvisorChain) {
var request = chatClientRequest;
ChatClientResponse response;
// Improved loop structure with better attempt counting and clearer logic
for (int attempt = 1; attempt <= maxRepeatAttempts + 1; attempt++) {
// Make the inner call (e.g., to the evaluation LLM model)
response = callAdvisorChain.copy(this).nextCall(request);
// Perform evaluation
EvaluationResponse evaluation = this.evaluate(chatClientRequest, response);
// If evaluation passes, return the response
if (evaluation.rating() >= this.successRating) {
logger.info("Evaluation passed on attempt {}, evaluation: {}", attempt, evaluation);
return response;
}
// If this is the last attempt, return the response regardless
if (attempt > maxRepeatAttempts) {
logger.warn(
"Maximum attempts ({}) reached. Returning last response despite failed evaluation. Use the following feedback to improve: {}",
maxRepeatAttempts, evaluation.feedback());
return response;
}
// Retry with evaluation feedback
logger.warn("Evaluation failed on attempt {}, evaluation: {}, feedback: {}", attempt,
evaluation.evaluation(), evaluation.feedback());
request = this.addEvaluationFeedback(chatClientRequest, evaluation);
}
// This should never be reached due to the loop logic above
throw new IllegalStateException("Unexpected loop exit in adviseCall");
}
/**
* Performs the evaluation using the LLM-as-a-Judge and returns the result.
*/
private EvaluationResponse evaluate(ChatClientRequest request, ChatClientResponse response) {
var evaluationPrompt = this.evaluationPromptTemplate.render(
Map.of("question", this.getPromptQuestion(request), "answer", this.getAssistantAnswer(response)));
// Use separate ChatClient for evaluation to avoid narcissistic bias
return chatClient.prompt(evaluationPrompt).call().entity(EvaluationResponse.class);
}
/**
* Creates a new request with evaluation feedback for retry.
*/
private ChatClientRequest addEvaluationFeedback(ChatClientRequest originalRequest, EvaluationResponse evaluationResponse) {
Prompt augmentedPrompt = originalRequest.prompt()
.augmentUserMessage(userMessage -> userMessage.mutate().text(String.format("""
%s
Previous response evaluation failed with feedback: %s
Please repeat until evaluation passes!
""", userMessage.getText(), evaluationResponse.feedback())).build());
return originalRequest.mutate().prompt(augmentedPrompt).build();
}
}
Recursive Pattern Implementation
The advisor uses callAdvisorChain.copy(this).nextCall(request) to create a sub-chain for recursive calls, enabling multiple evaluation rounds while maintaining proper advisor ordering.
Structured Evaluation Output
Using Spring AI's structured output capabilities, the evaluation results are parsed into a EvaluationResponse record with rating (1-4), evaluation rationale, and specific feedback for improvement.
Separate Evaluation Model
Uses a specialized LLM-as-a-Judge model (avcodes/flowaicom-flow-judge:q4) with a different ChatClient instance to mitigate model biases.
The spring.ai.chat.client.enabled=false is set to enable Working with Multiple Chat Models.
Feedback-Driven Improvement Failed evaluations include specific feedback that gets incorporated into retry attempts, enabling the system to learn from evaluation failures.
Configurable Retry Logic Supports configurable maximum attempts with graceful degradation when evaluation limits are reached.
Here's how to integrate the SelfRefineEvaluationAdvisor into a complete Spring AI application:
@SpringBootApplication
public class EvaluationAdvisorDemoApplication {
@Bean
CommandLineRunner commandLineRunner(AnthropicChatModel anthropicChatModel, OllamaChatModel ollamaChatModel) {
return args -> {
ChatClient chatClient = ChatClient.builder(anthropicChatModel) // @formatter:off
.defaultTools(new MyTools())
.defaultAdvisors(
SelfRefineEvaluationAdvisor.builder()
.chatClientBuilder(ChatClient.builder(ollamaChatModel)) // Separate model for evaluation
.maxRepeatAttempts(15)
.successRating(4)
.order(0)
.build(),
new MyLoggingAdvisor(2))
.build();
var answer = chatClient
.prompt("What is current weather in Paris?")
.call()
.content();
System.out.println(answer);
};
}
static class MyTools {
final int[] temperatures = {-125, 15, -255};
private final Random random = new Random();
@Tool(description = "Get the current weather for a given location")
public String weather(String location) {
int temperature = temperatures[random.nextInt(temperatures.length)];
System.out.println(">>> Tool Call responseTemp: " + temperature);
return "The current weather in " + location + " is sunny with a temperature of " + temperature + "°C.";
}
}
}
This configuration uses Anthropic Claude for generation and Ollama for evaluation (avoiding bias), requires rating of 4 with up to 15 retry attempts.
It includes weather tool that generates randomized responses to trigger evaluations.
The weather tool generates invalid values in 2/3 of the cases.
The SelfRefineEvaluationAdvisor (Order 0) evaluates response quality and retries with feedback if needed, followed by MyLoggingAdvisor (Order 2) which logs the final request/response for observability.
When run, you would see output like this:
REQUEST: [{"role":"user","content":"What is current weather in Paris?"}]
>>> Tool Call responseTemp: -255
Evaluation failed on attempt 1, evaluation: The response contains unrealistic temperature data, feedback: The temperature of -255°C is physically impossible and indicates a data error.
>>> Tool Call responseTemp: 15
Evaluation passed on attempt 2, evaluation: Excellent response with realistic weather data
RESPONSE: The current weather in Paris is sunny with a temperature of 15°C.
🚀 Try It Yourself: The complete runnable demo with configuration examples, including different model combinations and evaluation scenarios, is available in the evaluation-recursive-advisor-demo project.
Spring AI's Recursive Advisors make implementing LLM-as-a-Judge patterns both elegant and production-ready. The SelfRefineEvaluationAdvisor demonstrates how to build self-improving AI systems that automatically assess response quality, retry with feedback, and scale evaluation without human intervention.
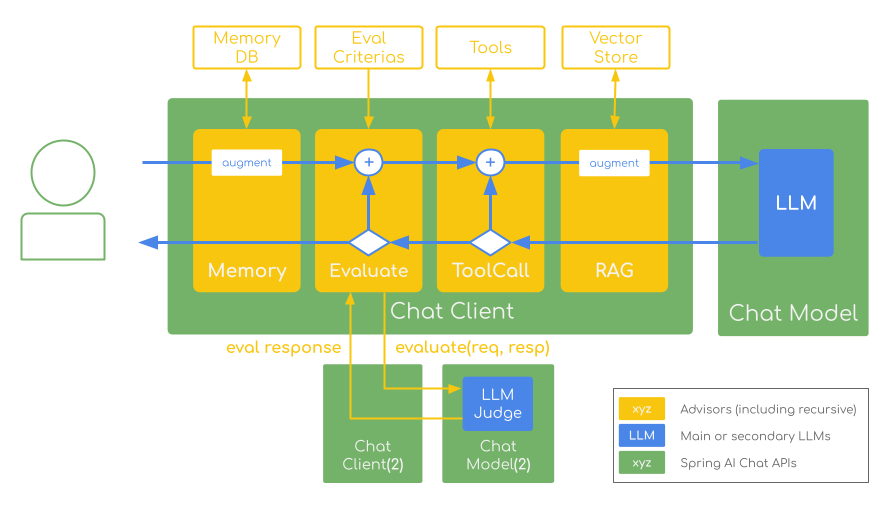
Key benefits include automated quality control, bias mitigation through separate judge models, and seamless integration with existing Spring AI applications. This approach provides the foundation for reliable, scalable quality assurance across chatbots, content generation, and complex AI workflows.
The critical success factors when implementing the LLM-as-a-Judge technique include:
⚠️ Important Note
Recursive Advisors are a new experimental feature in Spring AI 1.1.0-M4+. Currently, they are non-streaming only, require careful advisor ordering, and can increase costs due to multiple LLM calls.
Be especially careful with inner advisors that maintain external state - they may require extra attention to maintain correctness across iterations.
Always set termination conditions and retry limits to prevent infinite loops.
Spring AI Documentation
LLM-as-a-Judge Research

VMware offers training and certification to turbo-charge your progress.
Learn moreTanzu Spring offers support and binaries for OpenJDK™, Spring, and Apache Tomcat® in one simple subscription.
Learn moreCheck out all the upcoming events in the Spring community.
View all