Get ahead
VMware offers training and certification to turbo-charge your progress.
Learn moreA New Session API for Spring AI — Structured, Compactable, Multi-Agent-Ready
Part 7 of the Spring AI Agentic Patterns series completes the memory picture. After covering Agent Skills, AskUserQuestionTool, TodoWriteTool, Subagent Orchestration, A2A Integration, and AutoMemoryTools for long-term cross-session memory, we now add the complementary short-term layer: Spring AI Session. Storing conversation history as a flat message list works for short exchanges but breaks down as sessions grow — naive truncation silently discards tool-call sequences mid-exchange, leaving the model with orphaned results and broken turn structure. Spring AI Session solves this by automatically recording every message, tool call, and result for the active exchange and managing the context window intelligently, while AutoMemoryTools retains curated facts that must survive beyond the session. A complete agent memory stack needs both; neither replaces the other.
Roadmap: Incubating in spring-ai-community; targets Spring AI 2.1 (November 2026), when
ChatMemorywill be deprecated in its favour.
ChatMemory evicts the oldest messages with no turn safety, no event identity, no multi-agent support, and no record of what was discarded. Spring AI Session replaces it with an event-sourced log, pluggable compaction strategies, branch isolation, and keyword-searchable recall storage.
🚀 Want to jump right in? Skip to the Getting Started section.
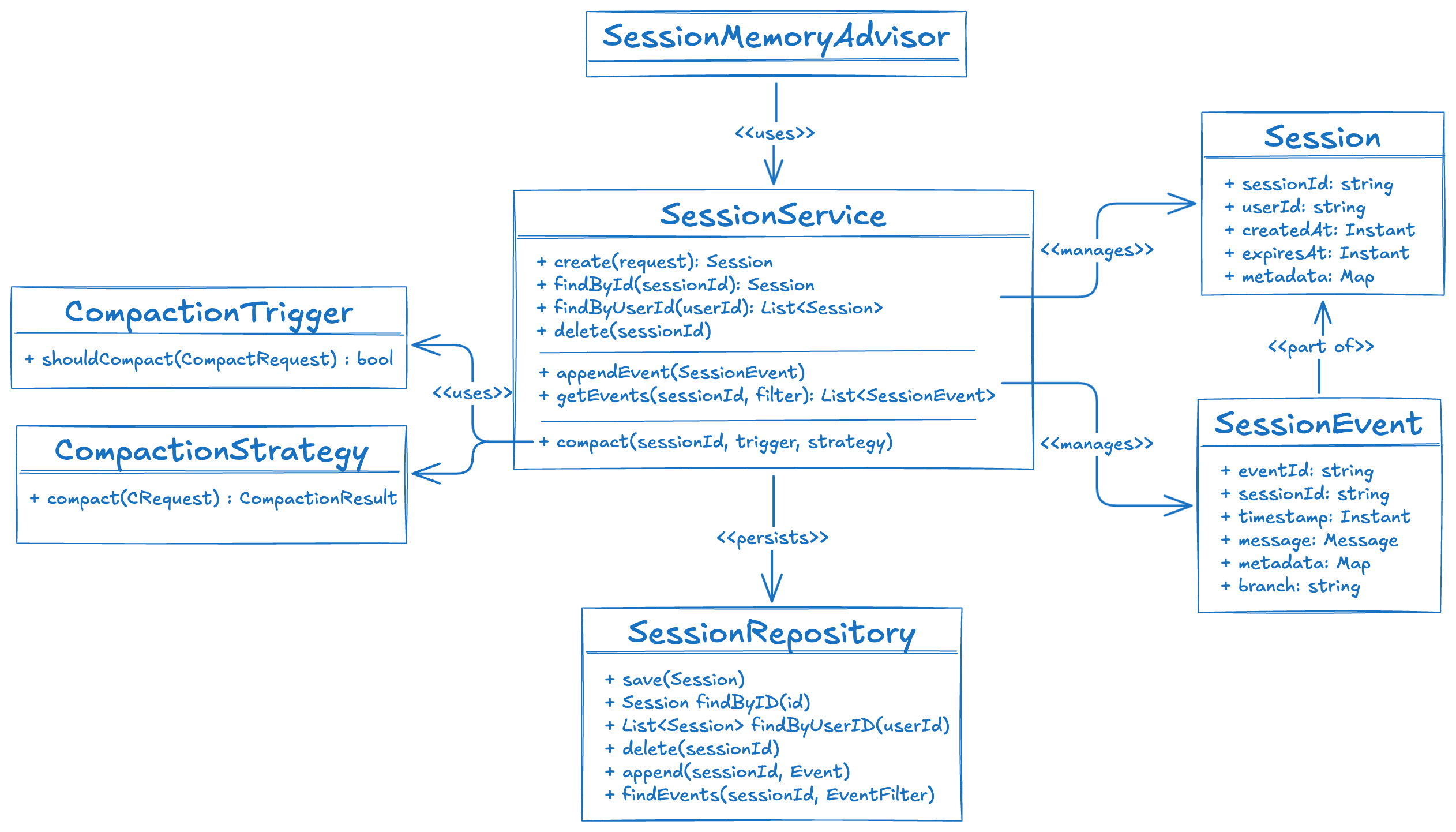
Session is an immutable metadata-only value object — it holds the session ID, user ID, TTL, and arbitrary metadata. The event log lives separately in the repository, fetched on demand.
SessionEvent wraps a Spring AI Message and adds what Message intentionally omits: a UUID, sessionId, timestamp, an optional branch label for multi-agent hierarchies, and framework flags like METADATA_SYNTHETIC.
SessionService service = new DefaultSessionService(InMemorySessionRepository.builder().build());
Session session = service.create(
CreateSessionRequest.builder().userId("alice").build()
);
service.appendMessage(session.id(), new UserMessage("What is Spring AI?"));
service.appendMessage(session.id(), new AssistantMessage("Spring AI is..."));
List<Message> history = service.getMessages(session.id()); // ready to pass to an LLM
A turn is the atomic unit of conversation: one UserMessage plus all following events — assistant replies, tool calls, tool results — up to the next UserMessage. All compaction strategies operate at turn granularity, so the kept window always starts on a USER message. The model never sees an orphaned tool result or a split exchange.
Turn 1: [USER "What is Spring AI?"] [ASSISTANT "Spring AI is..."]
Turn 2: [USER "Can it use tools?"] [ASSISTANT (tool call)] [TOOL result] [ASSISTANT "Yes,..."]
Compaction reduces the event history to fit the context window while preserving coherence. It is driven by two composable abstractions: triggers and strategies.
new TurnCountTrigger(20); // fires when > 20 turns
TokenCountTrigger.builder().threshold(4000).build(); // fires at 4000 estimated tokens
// OR-composite — fires if either condition is met
CompositeCompactionTrigger.anyOf(
new TurnCountTrigger(20),
TokenCountTrigger.builder().threshold(4000).build()
);
| Strategy | LLM call? | Best for |
|---|---|---|
SlidingWindowCompactionStrategy |
No | Cost-sensitive, short-term context |
TurnWindowCompactionStrategy |
No | Turn-structured dialogues |
TokenCountCompactionStrategy |
No | Hard context-window limits |
RecursiveSummarizationCompactionStrategy |
Yes | Long-running, context-rich sessions |
The first three keep a verbatim suffix of events (by message count, turn count, or token budget). All three snap the cut point to the nearest turn boundary — no partial turns are ever kept.
Recursive Summarization is the most powerful: it uses an LLM to summarize the events being archived and stores the result as a synthetic user + assistant turn. Each subsequent compaction pass builds on prior summaries — creating a rolling compressed history that never starts from scratch:
RecursiveSummarizationCompactionStrategy.builder(chatClient)
.maxEventsToKeep(10)
.overlapSize(2) // feed 2 events from the active window into the summary prompt
.build();
Note: Trigger and strategy must always be configured together — setting one without the other throws
IllegalArgumentExceptionat build time. Either set both via.compactionTrigger(...)and.compactionStrategy(...), or omit both to disable compaction entirely.
SessionMemoryAdvisor wires session management into the ChatClient pipeline transparently. On every request it loads history, prepends it to the prompt, appends the new user and assistant messages, and runs compaction if a trigger fires — all without any manual code in the application.
@Bean
SessionMemoryAdvisor sessionMemoryAdvisor(SessionService sessionService,
ChatClient.Builder chatClientBuilder) {
return SessionMemoryAdvisor.builder(sessionService)
.defaultUserId("alice")
.compactionTrigger(new TurnCountTrigger(20))
.compactionStrategy(
RecursiveSummarizationCompactionStrategy.builder(chatClientBuilder.build())
.maxEventsToKeep(10)
.build()
)
.build();
}
@Bean
ChatClient chatClient(ChatClient.Builder chatClientBuilder, SessionMemoryAdvisor advisor) {
return chatClientBuilder.defaultAdvisors(advisor).build();
}
Pass a session ID at call time via the advisor context:
String response = chatClient.prompt()
.user("Hello!")
.advisors(a -> a.param(SessionMemoryAdvisor.SESSION_ID_CONTEXT_KEY, "session-abc"))
.call()
.content();
If no session exists for the given ID, the advisor creates one automatically.
When an orchestrator fans out to parallel sub-agents, all agents can share the same Session — but each must see only its own events plus its ancestors'. SessionEvent.branch is a dot-separated path that records the producing agent's position in the hierarchy:
orchestrator branch = "orch"
├── researcher branch = "orch.researcher"
└── writer branch = "orch.writer"
Events with branch = null are root-level — visible to every agent. Pass EventFilter.forBranch() to apply isolation automatically inside the advisor:
// Researcher sees: null-branch + "orch" + own "orch.researcher" events
// Hidden: "orch.writer" (sibling)
SessionMemoryAdvisor researcherAdvisor = SessionMemoryAdvisor.builder(sessionService)
.defaultSessionId(sharedSessionId)
.eventFilter(EventFilter.forBranch("orch.researcher"))
.build();
Synthetic summary events from RecursiveSummarizationCompactionStrategy always carry branch = null, so compaction summaries remain visible to every agent in the session.
Compaction improves prompt efficiency, but older events are removed from the active context window. SessionEventTools implements the MemGPT Recall Storage pattern: the full verbatim event log is always retained and searchable by keyword, even after compaction has pruned it from the prompt.
ChatClient client = ChatClient.builder(chatModel)
.defaultTools(SessionEventTools.builder(sessionService).build())
.defaultAdvisors(advisor)
.build();
The conversation_search tool is auto-discovered by Spring AI. When the model needs to recall a prior exchange it calls the tool with a keyword and an optional page index; results come back as chronologically ordered JSON. Synthetic summary events are searchable too — their text is indexed in the recall store.
spring-ai-session-jdbc stores session data in two tables (AI_SESSION and AI_SESSION_EVENT, an append-only event log) with support for PostgreSQL, MySQL, MariaDB, and H2. The Spring Boot starter auto-configures everything:
<dependency>
<groupId>org.springaicommunity</groupId>
<artifactId>spring-ai-starter-session-jdbc</artifactId>
</dependency>
For PostgreSQL or MySQL, enable schema initialisation:
spring:
ai:
session:
repository:
jdbc:
initialize-schema: always
No additional bean declarations are required.
Requirements: Java 17+, Spring AI 2.0.0-M4+, Spring Boot 4.0.2+
1. Import the BOM:
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springaicommunity</groupId>
<artifactId>spring-ai-session-bom</artifactId>
<version>0.2.0</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
2. Add a starter — JDBC for production, or spring-ai-session-management alone for in-memory development:
<dependency>
<groupId>org.springaicommunity</groupId>
<artifactId>spring-ai-starter-session-jdbc</artifactId>
</dependency>
3. Wire the advisor and use it:
@Bean
SessionMemoryAdvisor sessionMemoryAdvisor(SessionService sessionService) {
return SessionMemoryAdvisor.builder(sessionService)
.defaultUserId("alice")
.compactionTrigger(new TurnCountTrigger(20))
.compactionStrategy(SlidingWindowCompactionStrategy.builder().maxEvents(10).build())
.build();
}
@Bean
ChatClient chatClient(ChatModel chatModel, SessionMemoryAdvisor advisor) {
return ChatClient.builder(chatModel).defaultAdvisors(advisor).build();
}
Session session = sessionService.create(
CreateSessionRequest.builder().userId("alice").build()
);
String response = chatClient.prompt()
.user("What is Spring AI?")
.advisors(a -> a.param(SessionMemoryAdvisor.SESSION_ID_CONTEXT_KEY, session.id()))
.call()
.content();
The Session API is designed to replace ChatMemory as Spring AI's primary conversation persistence abstraction:
ChatMemory |
Spring AI Session | |
|---|---|---|
| Storage unit | Message (flat list) |
SessionEvent (immutable, timestamped, identified) |
| Compaction | Evict oldest messages | Four pluggable strategies incl. LLM summarization |
| Turn safety | Not enforced | All strategies snap to turn boundaries |
| Multi-agent | Not supported | Branch isolation with dot-separated labels |
| Recall search | Not available | conversation_search tool via SessionEventTools |
| Concurrency | Implementation-dependent | Optimistic CAS write in all implementations |
The equivalent of MessageWindowChatMemory.builder().maxMessages(20).build() is:
SessionMemoryAdvisor.builder(sessionService)
.compactionTrigger(new TurnCountTrigger(20))
.compactionStrategy(SlidingWindowCompactionStrategy.builder().maxEvents(20).build())
.build();
Spring AI Session brings a structured, event-sourced short-term memory layer to the Spring AI ecosystem — with turn-safe compaction, LLM-powered summarization, multi-agent branch isolation, and keyword-searchable recall storage. Paired with AutoMemoryTools from Part 6, you now have both halves of a complete agent memory stack: a durable long-term layer for facts that outlive the session, and a coherent short-term layer for the active conversation. The library is available from the spring-ai-community organization.

VMware offers training and certification to turbo-charge your progress.
Learn moreTanzu Spring offers support and binaries for OpenJDK™, Spring, and Apache Tomcat® in one simple subscription.
Learn moreCheck out all the upcoming events in the Spring community.
View all